Always be shippable
Drupal will soon be 15 years old, and 5 of that will be spent on building Drupal 8 – a third of Drupal's life. We started work on Drupal early in 2011 and targeted December 1, 2012 as the original code freeze date. Now almost three years later, we still haven't released Drupal 8. While we are close to the release of Drupal 8, I'm sure many many of you are wondering why it took 3 years to stabilize. It is not like we didn't work hard or that we aren't smart people. Quite the contrary, the Drupal community has some of the most dedicated, hardest working and smartest people I know. Many spent evenings and weekends pushing to get Drupal 8 across the finish line. No one individual or group is to blame for the delay – except maybe me as the project lead for not having learned fast enough from previous release cycles.
§Trunk-based development
The past 15 years we used "trunk-based development"; we built new features in incremental steps, maintained in a single branch called "trunk". We'd receive the feature's first patch, commit it to our main branch, put it behind us, and move on to the next patch. Trunk-based development requires a lot of discipline and as a community we have mostly mastered this style of development. We invested heavily in our testing infrastructure and established a lot of processes. For all patches, we had various people reviewing the work to make sure it was solid. We also had different people figure out and review all the required follow-up work to complete the feature. The next steps are carefully planned and laid out for everyone to see in what we call "meta" issues. The idea of splitting one large feature into smaller tasks is not a bad idea; it helps to make things manageable for everyone involved.
Given all this rigor, how do you explain the delays then? The problem is that once these features and plans meet reality, they fall apart. Some features such as Drupal 8's configuration management system had to be rewritten multiple times based on our experience using it despite passing a rigorous review process. Other features such as our work on URL routing, entity base fields and Twig templating required much more follow-up work compared to what was initially estimated. It turns out that breaking up a large task into smaller ones requires a lot of knowledge and vision. It's often impossible to estimate the total impact of a larger feature on other subsystems, overall performance, etc. In other cases, the people working on the feature lacked time or interest to do the follow-up work, leaving it to others to complete. We should realize is that this is how things work in a complex world and not something we are likely to change.
The real problem is the fact that our main branch isn't kept in a shippable state. A lot of patches get committed that require follow-up work, and until that follow-up work is completed, we can't release a new version of Drupal. We can only release as fast as the slowest feature, and this is the key reason why the Drupal 8 release is delayed by years.

We need a better way of working – one that conforms to the realities of the world we live in – and we need to start using it the day Drupal 8.0.0 is released. Instead of ignoring reality and killing ourselves trying to meet unrealistic release goals, we need to change the process.
§Feature branch workflow
The most important thing we have to do is keep our main branch in a shippable state. In an ideal world, each commit or merge into the main branch gives birth to a release candidate – it should be safe to release after each commit. This means we have to stop committing patches that put our main branch in an unshippable state.
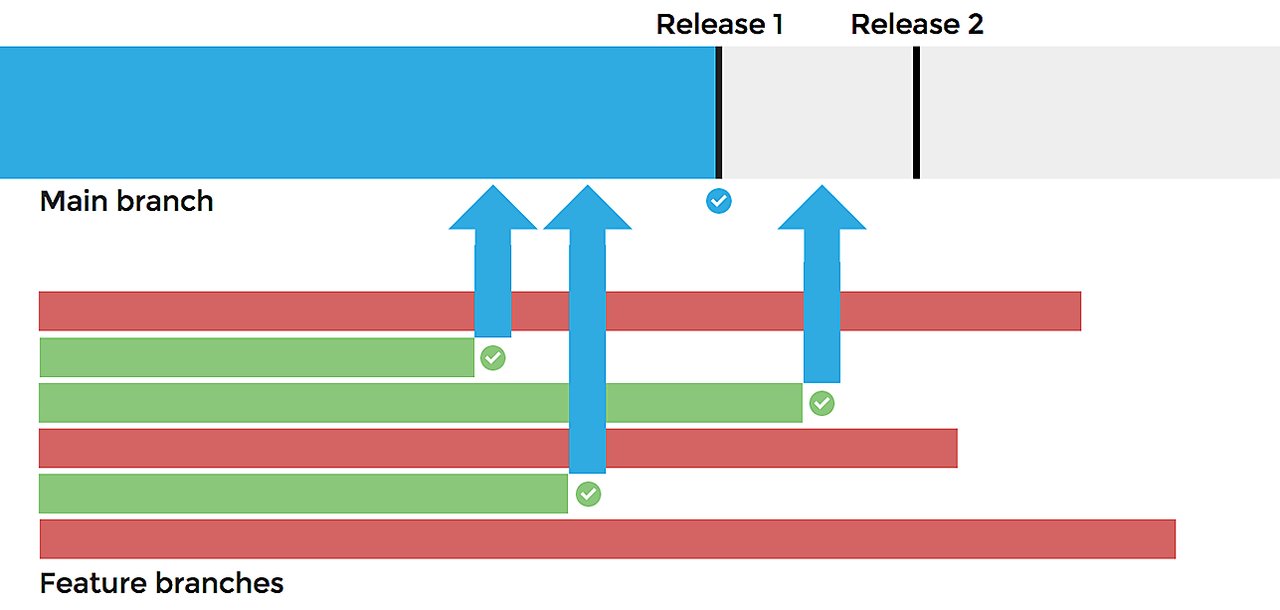
While this can be achieved using a trunk-based workflow, a newer and better workflow called "feature branch workflows" has become popular. The idea is that (1) each new feature is developed in its own branch instead of the main branch and that (2) the main branch only contains shippable code.
Keeping the main branch shippable at all times enables us to do frequent date-based releases. If a specific feature takes too long, development can continue in the feature branch, and we can release without it. Or when we are uncertain about a feature's robustness or performance, rather than delaying the release, it will simply have to wait until the next release. The maintainers decide to merge in a feature branch based on objective and subjective criteria. Objectively, the test suite must pass, the git history must be clean, etc. Subjectively, the feature must deliver value to the users while maintaining desirable characteristics like consistency (code, API, UX), high performance, etc.
Date-based releases are widely adopted in the Open Source community (Ubuntu, OpenStack, Android) and are healthy for Open Source projects; they reduce the time it takes for a given feature to become available to the public. This encourages contribution and is in line with the "release early, release often" mantra. We agreed on the benefits and committed to date-based releases following 8.0.0, so this simply aligns the tooling to make it happen.
Feature branch workflows have challenges. Reviewing a feature branch late in its development cycle can be challenging. There is a lot of change and discussion already incorporated. When a feature does finally integrate into main, a lot of change hits all at once. This can be psychologically uncomfortable. In addition, this can be disruptive to the other feature branches in progress. There is no way to avoid this disruption - someone has to integrate first. Release managers minimize the disruption by prioritizing high priority or low disruption feature branches over others.
Here is a workflow that could give us the best of both worlds. We create a feature branch for each major feature and only core committers can commit to feature branches. A team working on a feature would work in a sandbox or submit patches like we do today. Instead of committing patches to the main branch, core committers would commit patches to the corresponding feature branch. This ensures that we maintain our code review process with smaller changes that might not be shippable in isolation. Once we believe a feature branch to be in a shippable state, and it has received sufficient testing, we merge the feature branch into the main branch. A merge like this wouldn't require detailed code review.
Feature branches are also not the silver bullet to all problems we encountered with the Drupal 8 release cycle. We should keep looking for improvements and build them into our workflows to make life easier for ourselves and those we are implementing Drupal for. More on those in future posts.
Join 5,000+ readers. I'm the creator of Drupal and co-founder of Acquia. I write about Open Source, AI, and the future of the web, with a focus on building, scaling, and thinking long-term.